

A few months back, Facebook’s parent company Meta hinted that it was working on an open-source large language model that would outperform private models. On July 23, 2024, they released the model.
Meta’s recently released Llama 3.1 405B is the largest-ever open-source artificial intelligence (AI) model. Announcing the release in a blog post, Meta said, “We’re publicly releasing Meta Llama 3.1 405B, which we believe is the world’s largest and most capable openly available foundation model.”
Llama 3.1 405B is the first freely accessible model that can compete with the best AI models in terms of general knowledge, steerability, math, tool use, and language translation. Meta is launching improved versions of the 8B and 70B models. These are multilingual, with a greater context length of 128K, and overall stronger reasoning ability.
Meta’s CEO Mark Zuckerberg expects that from next year onwards the Llama models will be the most advanced in the industry.
How Is Meta Llama 3 Better Than Claude 3 Sonnet & Gemini Pro 1.5? Check Here
Key Features
These are the key features of the newly released Llama 3.1 models:
- Context Length- Llama 3.1 models have an expanded context length of 128K tokens that allows for more complex and lengthy interactions.
- Multilingual Support- The models also include support across eight languages.
- Llama 3.1 405B- Meta’s flagship model, Llama 3.1 405B, is the first open-source AI model of its caliber. It has unmatched flexibility, control, and capabilities that can rival the best closed-source models.
Performance and Benchmarks
Llama 3.1 uses a typical decoder-only transformer model design, with minimal modifications. The 405B parameter model was trained on almost 15 trillion tokens utilizing 16 thousand H100 GPUs, making it the most powerful Llama model to date.
Meta analyzed the performance of Llama 3.1 models on more than 150 benchmark datasets from a variety of languages. Also, they conducted human evaluations comparing Llama 3.1 to competing models in real-world circumstances.
Meta claims that the testing results show that Llama 3.1 405B can compete with leading foundation models- GPT-4, GPT-4o, and Claude 3.5 Sonnet- on different tasks. Let’s take a detailed look:
| Category | Benchmark | Llama 3.1 405B | Nemotron 4 340B Instruct | GPT-4 (0125) | GPT-4 Omni | Claude 3.5 Sonnet |
| General | MMLU (0-shot, CoT) | 88.6 | 78.7 (non-CoT) | 85.4 | 88.7 | 88.3 |
| MMLU PRO (5-shot, CoT) | 73.3 | 62.7 | 64.8 | 74.0 | 77.0 | |
| IFEval | 88.6 | 85.1 | 84.3 | 85.6 | 88.0 | |
| Code | HumanEval (0-shot) | 89.0 | 73.2 | 86.6 | 90.2 | 92.0 |
| MBPP EvalPlus (base) (0-shot) | 88.6 | 72.8 | 83.6 | 87.8 | 90.5 | |
| Math | GSM8K (8-shot, CoT) | 96.8 | 92.3 (0-shot) | 94.2 | 96.1 | 96.4 (0-shot) |
| MATH (0-shot, CoT) | 73.8 | 41.1 | 64.5 | 76.6 | 71.1 | |
| Reasoning | ARC Challenge (0-shot) | 96.9 | 94.6 | 96.4 | 96.7 | 96.7 |
| GPOQA (0-shot, CoT) | 51.1 | – | 41.4 | 53.6 | 59.4 | |
| Tool use | BFCL | 88.5 | 86.5 | 88.3 | 80.5 | 90.2 |
| Nexus | 58.7 | – | 50.3 | 56.1 | 45.7 | |
| Long context | ZeroSCROLLS/QuALITY | 95.2 | – | – | 95.2 | 90.5 |
| InfiniteBench/En.MC | 83.4 | – | 72.1 | 82.5 | – | |
| NIH/Multi-needle | 98.1 | – | 100.0 | 100.0 | 90.8 | |
| Multilingual | Multilingual MGSM | 91.6 | – | 85.9 | 90.5 | 91.6 |
| Category | Benchmark | Llama 3.1 8B | Gemma 2 9B IT | Mistral 7B Instruct | Llama 3.1 70B | Mixtral 8x22B Instruct | GPT 3.5 Turbo |
| General | MMLU (0-shot, CoT) | 73.0 | 72.3 (5-shot, non-CoT) | 60.5 | 86.0 | 79.9 | 69.8 |
| MMLU PRO (5-shot, CoT) | 48.3 | – | 36.9 | 66.4 | 56.3 | 49.2 | |
| IFEval | 80.4 | 73.6 | 57.6 | 87.5 | 72.7 | 69.9 | |
| Code | HumanEval (0-shot) | 72.6 | 54.3 | 40.2 | 80.5 | 75.6 | 68.0 |
| MBPP EvalPlus (base) (0-shot) | 72.8 | 71.7 | 49.5 | 86.0 | 78.6 | 82.0 | |
| Math | GSM8K (8-shot, CoT) | 84.5 | 76.7 | 53.2 | 95.1 | 88.2 | 81.6 |
| MATH (0-shot, CoT) | 51.9 | 44.3 | 13.0 | 68.0 | 54.1 | 43.1 | |
| Reasoning | ARC Challenge (0-shot) | 83.4 | 87.6 | 74.2 | 94.8 | 88.7 | 83.7 |
| GPOQA (0-shot, CoT) | 32.8 | – | 28.8 | 46.7 | 33.3 | 30.8 | |
| Tool use | BFCL | 76.1 | – | 60.4 | 84.8 | – | 85.9 |
| Nexus | 38.5 | 30.0 | 24.7 | 56.7 | 48.5 | 37.2 | |
| Long context | ZeroSCROLLS/QuALITY | 81.0 | – | – | 90.5 | – | – |
| InfiniteBench/En.MC | 65.1 | – | – | 78.2 | – | – | |
| NIH/Multi-needle | 98.8 | – | – | 97.5 | – | – | |
| Multilingual | Multilingual MGSM (0-shot) | 68.9 | 53.2 | 29.9 | 86.9 | 71.1 | 51.4 |
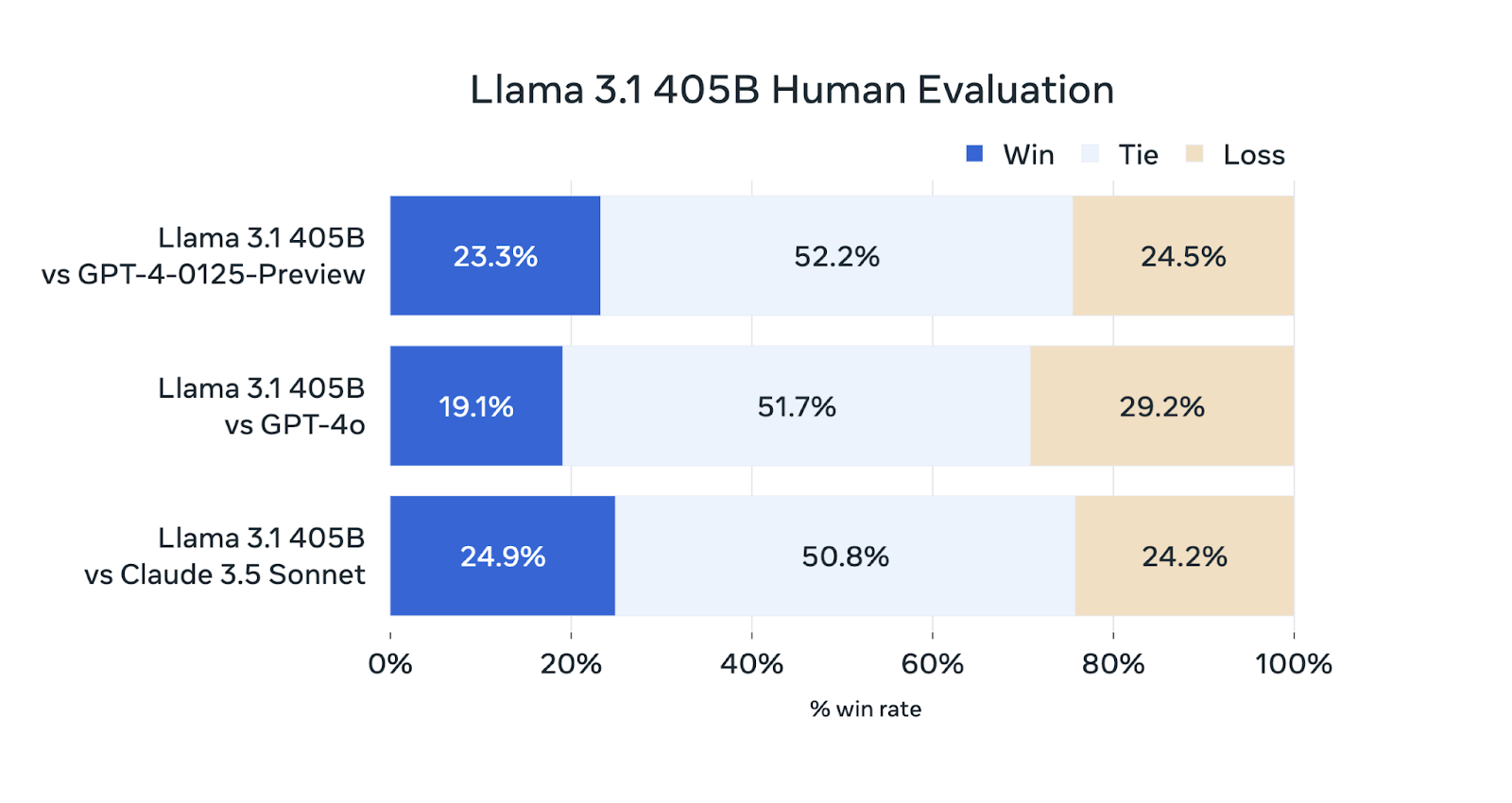
Human Evaluation
When testing their flagship model Llama 3.1 405B against its competitors like GPT-4-0125-Preview, GPT-4o, and Claude 3.5 Sonnet, the following results were found. Llama 3.1 405B shows a win record of 23.3% against GPT-4-0125-Preview, 19.1% against GPT-4o, and 24.9% against Claude 3.5 Sonnet, with ties at 52.2%, 51.7%, and 50.8%.
Pricing
Here is a table depicting Llama 3.1 inference API public pricing per million tokens:
| Model | 5B | 70B | 405B | |||
| Input | Output | Input | Output | Input | Output | |
| AWS | $0.30 | $0.60 | $2.65 | $3.50 | – | – |
| Azure | $0.30 | $0.61 | $2.68 | $3.54 | $5.33 | $16.00 |
| Databricks | – | – | $1.00 | $3.00 | $10.00 | $30.00 |
| Fireworks.ai | $0.20 | $0.20 | $0.90 | $0.90 | $3.00 | $3.00 |
| IBM | $0.60 | $0.60 | $1.80 | $1.80 | $35.00 | $35.00 |
| Octo.ai | $0.15 | $0.15 | $0.90 | $0.90 | $3.00 | $9.00 |
| Snowflake | $0.57 | $0.57 | $3.63 | $3.63 | $15.00 | $15.00 |
| Together.AI | $0.18 | $0.18 | $0.88 | $0.88 | $5.00 | $15.00 |
Meta AI vs ChatGPT: Which One is Better and Best?
Accessibility
Llama 3.1 models are available for download on llama.meta.com and Hugging Face. They are also ready for immediate development on various partner platforms, including AWS, NVIDIA, and Databricks.

The Bottom Line
The release of Llama 3.1 models has the whole tech community in a grapple. From Twitter to Reddit, every enthusiast is talking about Meta and its latest open-source LLM. If you would like to test the LLM, then head over to https://llama.meta.com/ and see for yourself.
Claude 3.5 Sonnet vs GPT-4o vs Gemini 1.5: Which is the Most Powerful AI Model?












