

Introduction
If you know anything about data validation, you must know how vital it is to maintain the accuracy and integrity of data. And speaking of data validation, one of the best tools to perform data validation is Pandera. Pandera – a data validation library – does this important task effortlessly. This Python library comes in the form of an open-source application programming interface (API) and is able to make data validation a cakewalk. As of July 2023, Pandera acquired over 2.5k GitHub stars. In this article, we will try to explore what Pandera is in Python, how it works, and all the other things that need to be mentioned.
Also Read: What are Small Language Models and how do they work?
History
Pandera’s journey began in 2018 with the help of Nigel Markey. This lightweight, flexible, and expressive API for validating pandas DataFrames has since improved with bug fixes, feature enhancements, and documentation improvements. Four major events in Pandera’s development include documentation improvements, support for a class-based API, data synthesis strategies, and the Pandera-type system.
The first major contribution came from Nigel Markey. He made Pandera easy to learn and adopt through examples, tutorials, and a comprehensive API reference. Jean-Francois Zinque implemented a class-based syntax, modernizing Pandera to use familiar syntax for developers. The third major improvement was the addition of support for data synthesis strategies using the hypothesis library. This expanded Pandera’s scope from a data validation library to a data testing toolkit. The fourth major improvement was the implementation of Pandera’s type system. This provided a consistent interface for defining semantic and logical types for pandas and other dataframe libraries.
Also Read: What is Scribble Diffusion? How Does It Turn Doodles and Sketches to AI Images?
What is Pandera in Python?
Pandera is a popular Union.ai open-source project. It offers a flexible and expressive API for data validation purposes on objects that are like dataframes. This API is super flexible and expressive. That’s why it is easy to create a solid and reliable data pipeline using Pandera. The main elements in Pandera are three things – DataFrameSchema, Column, and Check. Using them together, users can construct schema contracts by configuring logically grouped sets of validation rules that run on pandas DataFrames in advance. The API performs various tasks. These are:
- Designates schemas and validates those in various dataframe types. These include pandas, koalas, dask, and modin.
- Looks at the data types and characteristics of the columns/features in a pd.DataFrame, or the values in a pd.Series.
- Carries out advanced statistical checks like hypothesis testing.
- Incorporates validations into your present data analysis or processing pipelines by using function decorators.
- Creates schema models using a class-based API with a pydantic-style syntax, Then validates your data frames with typing syntax.
- Combines data from schema objects for property-based testing. Uses pandas data structures for that purpose.
- Validates data frames in a lazy manner, ensuring all validation rules are checked before any errors are thrown.
Here’s a simple rundown of Pandera’s setup. See the data flow diagram below. In the easiest case, raw data is fed into a data processor that carries out different tasks to extract, transform, or sort the info. Once that’s done, a schema checker validates the data before it proceeds to the next stage:
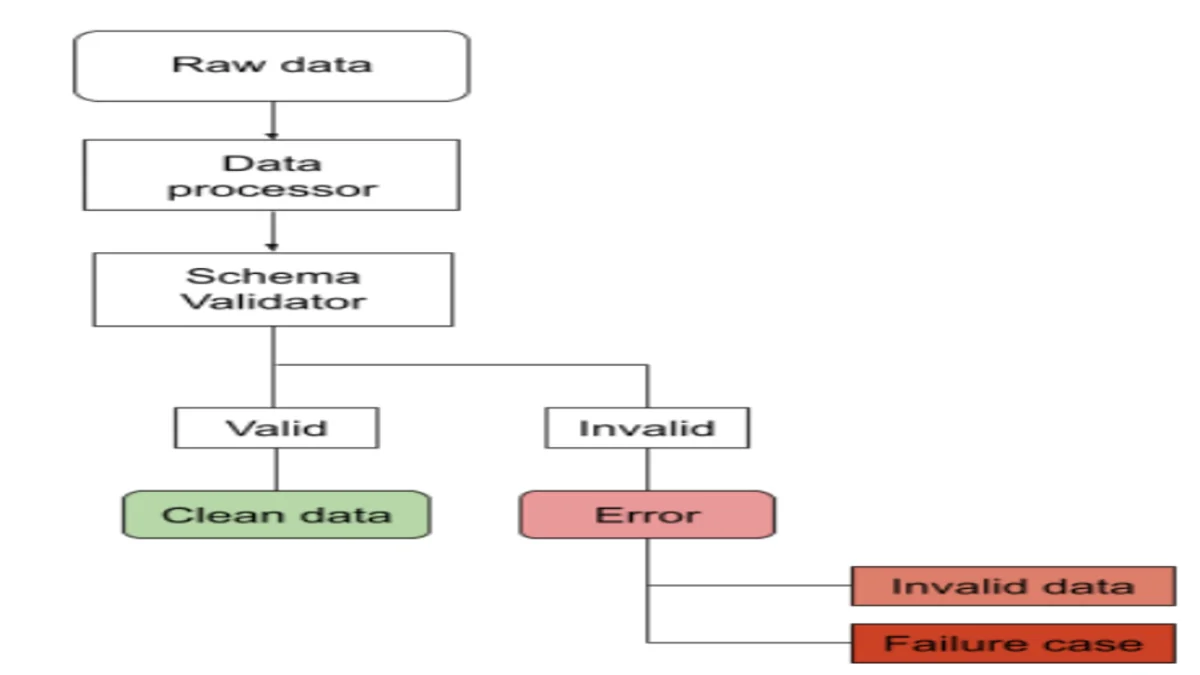
Source: analyticsindiamag
Key Data Validation Perks
Data validation is a vital thing in the computing world. Its perks are many. Some of them include:
- Better data quality
- Fewer mistakes
- More consistent data
- Increased data reliability
- Wiser decision-making
- Less data entry blunders
- Quicker data processing
- Meeting compliance and regulations
- Intuitive interfaces that are easy to use
Pandera helps data scientists and machine learning engineers achieve many things. Using Pandera, you can:
- Build intricate schemas rapidly and with ease. Make the most of Pandera’s zero-configuration API to create schemas using up-to-date Pythonic styles.
- Check the key areas of your pipeline. Pinpoint the essential points in your data pipeline and ensure the data flowing in and out is accurate.
- Kick off your schemas quickly with reliable data. Bypass the challenge of schema definition by deriving one from clean data, and refine it as you collect more insights.
- Quickly set up your own validation checks. Pick from a wide range of built-in tests or whip up your own rules tailored to your needs.
- Produce some mock data to make sure that your pipelines are working properly. Validate the functions that generate your data by auto-creating test cases for them.
Also Read: NLP vs LLM: What are the Chief Differences Between Them?
How Does Pandera in Python Work?
Pandera is a great tool to opt for if data validation is your primary goal. It achieves its objectives by doing a couple of important things:
Validating the Data Type
Pandera is super useful, as it helps you check the types of incoming raw data. This way, your data pipeline can catch issues early on. This stops any messed-up data from having a negative impact on important applications later. These applications could be anything from analytics to stats and machine learning, all of which need clean data to work properly.
Pandera is set up to validate pandas dataframes right out of the box. This indicates that its schemas can handle all the data types that pandas does. Some of them are:
- Standard Python types like int, bool, str, and float
- Numpy types such as numpy.int_ and numpy.bool_
- Types that are Pandas-specific. These include pd.StringDtype, pd.DatetimeTZDtype, and pd.BooleanDtype
- Any other string aliases that pandas recognizes
Coercing the Data Type
Generally, Pandera is a validation library that focuses primarily on the validation of schema metadata or data values in a dataframe without modifying the contents of the said dataframe.
However, there are instances when it is more suitable to convert or change the data values to comply with the data contract specified in the Pandera schema. At this point, the only transformation that Pandera does is type coercion, which can be turned on using the coerce=True argument while defining a schema or parts of it.
- Column
- Index
- MultiIndex
- DataFrameSchema
- SeriesSchema
Whenever this argument is applied, rather than simply inspecting the columns or index in search of the correct types, schema.validate will try to coerce the incoming dataframe values into the defined data types. After that, it will perform validation checks at the dataframe level, column level, and index level, all of which are just validation checks.
Also Read: From Idea to App: What is Google Stitch AI? A New Coding Tool to Help Design Apps
The nullable argument can be defined at the column-, index, or SeriesSchema- level. This is an essential check in Pandera. It is applied after the data type check or coercion process that we mentioned previously. As a result, data types that are inherently non-nullable will not pass even if you indicate nullable=True. That is because Pandera views type checks as a primary concern that is distinct from any further checks you may go for later.
Step-By-Step Process to Implement Pandera in Python
Implementing Pandera in Python may be a tricky task. But it can become easy if you follow the below steps correctly:
Installation:
Install Pandera using pip:

Or, you can also install it using conda:

Quick Start:
You can facilitate a quick start using the following code:


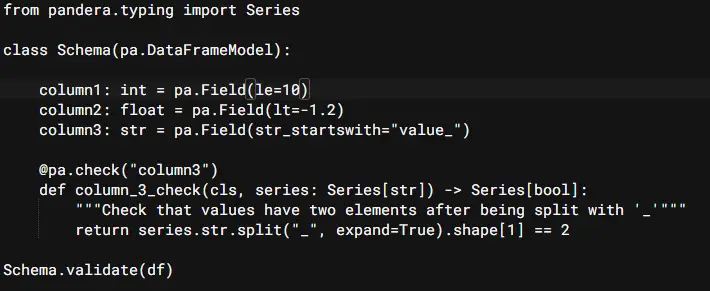
Dataframe Model:
Pandera provides another alternative API for the schema creation, which is inspired by dataclasses and pydantic. The corresponding DataFrameModel for the DataFrameSchema depicted above would be:
Development Installation:
The development installation can done using the below code:

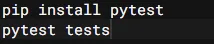
Running Tests:
You can run tests to see if everything is working as intended by executing the following command:

Source: towardsdatascience
Definition With an Example
Pandera has great use in the field of data science. Towards Data Science recently published an article that highlighted Pandera’s role in ensuring data integrity. We all know that data science is a complex thing. Here, data is the core element. So maintaining its quality and consistency is vital. Pandera steps in to uphold data integrity via thorough validation. It goes beyond just checking data types or formats. Pandera tackles more advanced statistical validations, too, thereby making it a vital partner in your data science projects. Below are some things that make Pandera special:
- Schema Enforcement: Ensures your DataFrame sticks to a set schema.
- Customizable Validation: Lets you create intricate, tailored validation rules.
- Integration with Pandas: Works smoothly with your current pandas workflows.
Data science firms often incorporate Pandera into their data processing pipeline. This helps them detect inconsistencies and errors early. It is not only time-saving but also ensures better and more reliable data analysis down the road.
Conclusion
To conclude, Pandera is a solid Python library for data validation and testing. It helps you make sure that the data you’re handling is compliant to defined structure, values, etc. Using the defined rules and restrictions, Pandera can auto-check for errors and lack of consistency to identify issues before they get out of hand. Pretty convenient, if you ask us!
For more informations on AI, click on the link given below:












