

AI research and development firm, OpenAI, recently announced the release of a new large language model (LLM), OpenAI o1. The OpenAI o1 model series has been developed “to spend more time thinking before they respond.” They exhibit exceptional capabilities in complex reasoning tasks and outperform their predecessors in science, coding, and mathematics.
This new LLM is designed to excel at complex reasoning and problem-solving tasks. This article will cover the key benchmarks, performance improvements, and how to access OpenAI o1.
OpenAI Launches GPT-4o Fine-Tuning: Boost Performance with Custom Training
Benchmarks and Performance
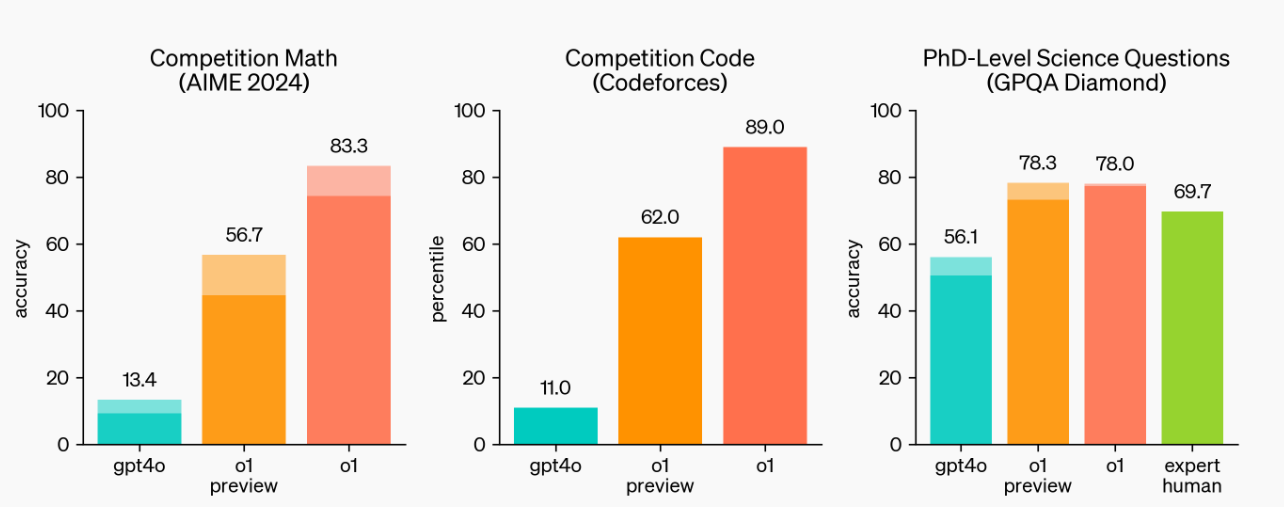
According to this technical research post, OpenAI’s o1 model demonstrated exceptional performance across various academic domains. It ranked in the top 11% on Codeforces, qualified for the AIME (top 500 in the US), and outperformed human PhD-level experts in physics, biology, and chemistry.
Source: OpenAI
The model’s accuracy and reasoning capabilities were tested on:
- AIME 2024 (Math): OpenAI o1’s accuracy reached 93% with re-ranking, placing it in the top 500 U.S. math students. o1 averaged 83% accuracy using 64 samples and an impressive 93% with re-ranking from 1,000 samples.
- GPQA Diamond (Science): On the GPQA Diamond benchmark, which includes complex problems in physics, biology, and chemistry, o1 became the first AI model to surpass PhD-level human performance.
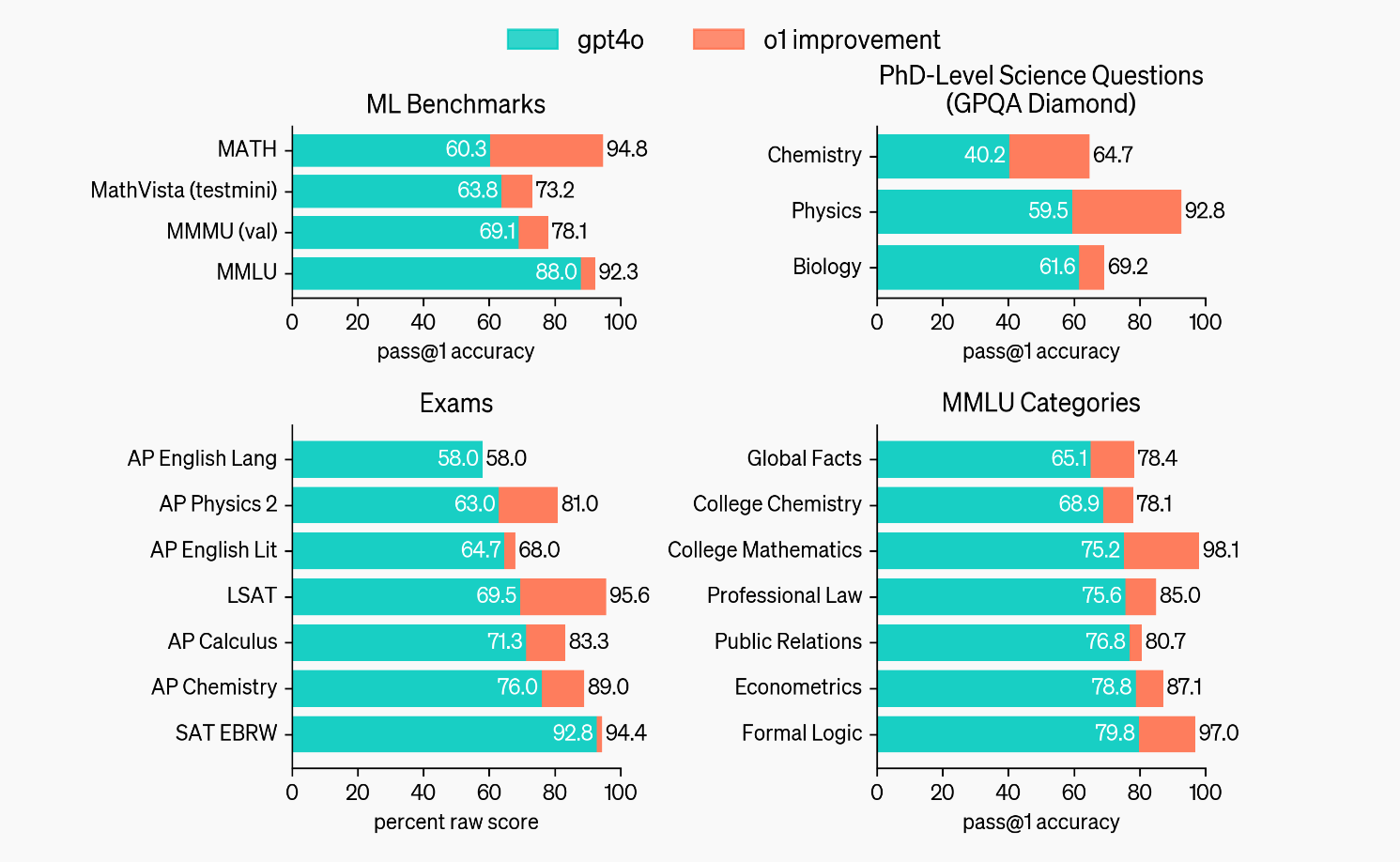
- MMLU (Multi-task Language Understanding): It showed improved performance across 54/57 subcategories, making it competitive with human experts. OpenAI o1 also shined in coding competitions. In the International Olympiad in Informatics (IOI), the model scored 213 points and placed in the 49th percentile of human contestants
- Codeforces: The OpneAI o1 model achieved a higher Elo rating than 89% of human participants in competitive coding. While GPT-4o achieved an Elo rating of 808, o1 surpassed 93% of competitors with an Elo rating of 1807.
Source: OpenAI
What is OpenAI System Card and How is GPT-4o Following AI Safety Measures?
Human Preference Evaluation
Although OpenAI’s o1 model is skilled at tasks that require logical reasoning, it may not always outperform GPT-4o in natural language tasks. While human evaluators favored o1’s responses for tasks like data analysis, coding, and math, GPT-4o still excels in certain open-ended, language-focused areas.
OpenAI o1-mini
Alongside the o1-preview, OpenAI also introduced o1-mini. The 01-mini is a faster and more cost-effective version. Despite being smaller, it matches o1-preview in performance for math and coding tasks. It is perfect for users who want efficiency without compromising on reasoning quality.
How to Access OpenAI o1?
Currently, the o1 model is available only to ChatGPT Plus and select API users. OpenAI is rolling out the model for tier 5 developers, providing access to both o1-preview and o1-mini. o1-preview is designed to tackle complex tasks with broad world knowledge, while o1-mini offers a faster, cheaper alternative for more focused reasoning tasks like coding and math.
OpenAI’s AI Detection Tool Sparks Debate Over ChatGPT Watermarking
The Bottom Line
With the release of o1, OpenAI is trying to improve its LLM game. The new model is different from similar ones as it can consider complex problems before responding.
To sum up, the OpenAI o1 model is a great tool for developers, researchers, and professionals who want an AI model capable of tackling the most challenging tasks.
Microsoft Lists OpenAI as Competitor Despite $13 Billion Investment













Der darüber hinausgehende Gewinn wird ihm direkt ausbezahlt.
Dieses Buch wird inzwischen mehr als Hunderte Mal zitiert, wenn es darum geht,
dass das „Roulette das fairste Glücksspiel” sei.
Telefonische oder persönliche Reservierungen für das Cash-Game werden täglich und frühestens 7 Tage
im Voraus ab 12.00 Uhr an der Rezeption entgegengenommen. Starten Sie einfach
Ihr Lieblingsspiel und lassen Sie die Walzen für sich arbeiten!
Die Spielbank Esplanade ist überwiegend barrierefrei und bietet umfassende Zugänglichkeit für Menschen mit Behinderungen. Durch die zentrale Lage ist das Spielcasino problemlos
zu erreichen. Für Reisende per Flugzeug bietet
sich der Flughafen Hamburg an. Hier haben wir nicht nur Texas Hold´em, sondern auch Pot Limit
Omaha gespielt. Gleichzeitig verfügt das Esplanade über ein gut ausgebautes Angebot an den Pokertischen. Aus dem
Osten de Republik geht es über die A24 direkt von Berlin nach Hamburg.
References:
https://online-spielhallen.de/rizk-casino-mobile-app-dein-spielvergnugen-fur-unterwegs/