
Have you ever faced a situation where a random term related to Artificial Intelligence confronted you?
What is the first question that comes to mind?
Googling that term seems like a much more obvious step. What if all the related terms about AI were available in one place?
Therefore, TechChilli has compiled an extensive collection of words and phrases that are essential for any professional involved in developing AI solutions.
Understanding the key terms and terminologies related to artificial intelligence is of utmost importance in today’s technology-driven world.
As artificial intelligence continues to permeate various industries and shape the future of innovation, having a solid grasp of the fundamental concepts and vocabulary is essential for professionals involved in AI development and implementation.
These terms not only provide a common language for communication and collaboration but also serve as building blocks for deeper comprehension and exploration of AI technologies. From foundational concepts like machine learning and neural networks to advanced topics like natural language processing and computer vision, a comprehensive understanding of AI terminology enables professionals to navigate the complexities of this rapidly evolving field and effectively contribute to the development and deployment of intelligent systems. Whether you are an AI researcher, developer, or decision-maker, familiarising yourself with these important terms empowers you to make informed decisions, effectively communicate ideas, and unlock the full potential of artificial intelligence in solving real-world challenges.
A
Accuracy: Accuracy is a statistical measure that quantifies the success of an AI model in predicting outcomes. It is calculated by dividing the number of correct predictions by the total number of predictions made, and it indicates the model’s overall performance. Formally, accuracy has the following definition:
Accuracy = Number of correct predictions/Total number of predictions
Activation: An activation function determines whether a neuron within a neural network should be activated based on its input. It plays a crucial role in determining the significance of the neuron’s input in the prediction process, using simple mathematical operations.
Active Learning: It is a subset of Machine Learning that can interactively query a user for labelled data with desired outputs. The algorithm proactively selects a subset of examples from the pool of unlabeled data that should be labeled next. The underlying principle of active learning is that a machine learning algorithm can potentially achieve higher accuracy by using a smaller number of training labels if it can choose the data from which it learns.
Adversarial Machine Learning: This is a particular field of artificial intelligence (AI) that focuses on studying and addressing vulnerabilities and attacks on machine learning models. It explores the potential risks and countermeasures associated with malicious actors intentionally manipulating or deceiving AI systems.

Adversarial Examples: In AML, adversaries aim to exploit the vulnerabilities of machine learning models by introducing carefully crafted input data, known as adversarial examples, to mislead or deceive the models. Adversarial examples are created by making small, imperceptible modifications to input data that can cause the machine learning model to produce incorrect predictions or classifications.
Algorithm:
An algorithm is a formula, a predefined set of rules, or a series of instructions used to solve a problem or accomplish a specific task. In the context of Artificial Intelligence, an algorithm instructs a machine on how to obtain answers to questions or solutions to problems. In machine learning, systems use many different types of algorithms. Some commonly used examples include decision trees, clustering algorithms, classification algorithms, and regression algorithms. These algorithms enable machines to process and analyze data, make predictions, and derive insights in a wide range of applications.
Also, Read – What is Generative AI
Anchor Box: Anchor boxes are predetermined bounding boxes with specific dimensions, typically chosen based on object sizes in training datasets, to capture the scale and aspect ratio of desired object classes for detection purposes.
When performing detection, these predefined anchor boxes are placed in a tiled manner across the image. The network predicts various attributes, including probability, background, intersection over union (IoU), and offsets, for each anchor box. These predictions are utilized to refine and adjust each anchor box individually.
Multiple anchor boxes can be defined, each catering to different object sizes. Anchor boxes serve as fixed initial guesses for bounding box boundaries. For example, small and square anchor boxes are typically used in the face detection model.

Image source: Mathworks.com
Annotation: AI annotation refers to the process of labelling or annotating data for training and improving artificial intelligence (AI) models. It involves manually or semi-automatically adding relevant annotations or metadata to datasets to provide meaningful information to the AI algorithms.
It is a critical step in supervised machine learning models. It involves annotating data samples with labels or annotations that represent the desired output or ground truth. For example, in image recognition tasks, annotations may involve drawing bounding boxes around objects of interest or labelling each pixel in an image.
In natural language processing, annotations could involve tagging parts of speech or identifying named entities in text.
Annotation Format: Annotation format refers to the specific structure and organization of annotations applied to data during the labelling or annotation process. It defines how the annotations are represented, stored, and interpreted, allowing for consistent and standardized handling of annotated data.
For example, the Bounding Box Annotation Format is used in computer vision tasks, particularly object detection and localization. It involves specifying the coordinates of a bounding box that encompasses an object or region of interest within an image or video.

Bounding Box showing co-ordinates x1, y1, x2, y2, width (w), and height (h) (Photo by an_vision on Unsplash)
Image Source: edge-ai-vision
Annotation Group: Annotation groups are a convenient way to manage and modify the appearance of multiple text elements, particularly in the context of coordinating annotations and visual components in map documents. They offer the advantage of associating a group with a specific layer, enabling automatic toggling of the visibility of its text when the layer is turned on or off.
The term “annotation group” encompasses all the classes or categories present in a dataset. It provides an answer to the question, “What are the types of items that have been labelled in this dataset?”
Application Programming Interface (API):
An Application Programming Interface (API) is a mechanism that facilitates communication and interaction between two distinct applications. APIs serve as the “handshaking” mechanism that enables applications to exchange data and request services from one another.
When you use an application on your mobile phone or device, the application establishes a connection to the internet and sends data to a server. The server receives the data, processes it, and sends a response back to your device. The application then interprets the received data and presents the desired information to you in a readable format. This entire process is made possible through the utilization of an API, which acts as an intermediary, facilitating communication between the application and the server.
Architecture: AI Architecture refers to the design and structure of an artificial intelligence (AI) system or model. It encompasses the arrangement and organization of components, algorithms, and processes involved in building and deploying AI solutions. AI architecture defines how different elements of an AI system interact and work together to achieve specific goals.
A well-designed architecture ensures that the AI model is capable of learning from data, making accurate predictions, and performing the desired tasks effectively. It also considers factors such as computational resources, data privacy, security, and real-time processing requirements.
Artificial Intelligence (AI): Artificial intelligence, also known as machine intelligence, pertains to systems that exhibit intelligent behavior through the analysis of their surroundings and the execution of actions, with a certain level of autonomy, to accomplish specific objectives. AI systems can exist purely in software form, operating within the virtual realm (e.g., voice assistants, image analysis software, search engines, speech, and facial recognition systems). Alternatively, AI can be integrated into hardware devices (e.g., advanced robots, autonomous vehicles, drones, or applications in the Internet of Things). The term “AI” was originally introduced by John McCarthy in 1956.
Basically, there are four distinct objectives that might be pursued in the field of Artificial Intelligence(AI)
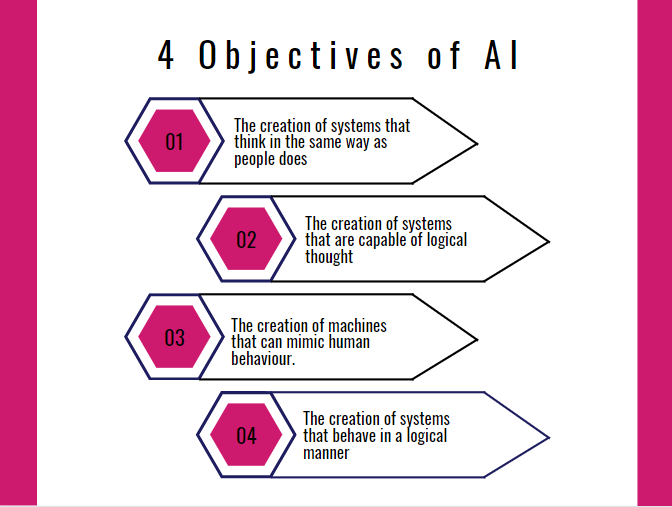
AI Ethics: Ethical considerations in the context of artificial intelligence pertain to a specialized field that focuses on the impact of biases within artificially intelligent systems. Machine learning, which heavily relies on training data, is susceptible to incorporating biases that span various dimensions such as gender, race, age, economic status, and more. These biases have the potential to significantly influence the outcomes and behaviors of AI systems.
AI framework: AI frameworks simplify and expedite the development of machine learning, deep learning, neural networks, and natural language processing (NLP) applications by providing pre-built solutions. Open-source frameworks like TensorFlow, Theano, PyTorch, Sci-Kit, Keras, Microsoft Cognitive Toolkit, and Apache Mahout are widely recognized and commonly used for this purpose. These frameworks offer a range of tools and libraries that empower developers to leverage existing resources, accelerating the implementation of AI applications.
AI Model Goodness Measurement Metrics: The evaluation of AI models created for specific tasks like classification, prediction, and clustering is conducted using a set of metrics known as AI model evaluation metrics. These metrics encompass various measurements to assess the quality of AI models, including accuracy, precision, recall, F-measure, word error rate, sentence error rate, mean absolute error, general language understanding evaluation (GLUE), and more.
Artificial Narrow Intelligence (ANI): It is also known as Weak AI or Narrow AI, which refers to a type of intelligence that is “simulated” rather than truly conscious. Systems classified as weak AI exhibit behavior that appears intelligent but lacks self-awareness or understanding of their actions. For instance, a chatbot may engage in conversation in a seemingly natural manner, but it lacks knowledge of its own identity or purpose for interacting with you.
Narrow AIs, in most cases, surpass human capabilities in the specific tasks they were designed for. Examples include face recognition, chess computers, calculus, and translation. Narrow artificial intelligence distinctly differs from strong AI, or artificial general intelligence, which seeks to create systems with consciousness or the capacity to solve any problem. Virtual assistants and AlphaGo are instances of artificially narrow intelligence systems.
Artificial General Intelligence (AGI), also referred to as Strong or General Artificial Intelligence (AGI) involves the ability to exhibit true cognition and thinking akin to that of a conscious human mind. In AGI, systems possess an awareness of their own identity, purpose, and actions, similar to how humans engage in meaningful conversations with self-awareness. AGI systems can perform tasks and possess capabilities that are comparable to human capabilities. These systems are typically more complex and challenging to comprehend. They are designed to handle situations where independent problem-solving is required, without relying on human assistance.
Examples of applications for such systems include self-driving cars and surgical operations in hospitals.
Artificial Super Intelligence (ASI), often referred to as superintelligence, signifies a level of general and strong AI that surpasses human intelligence, if such a level is attainable. Superintelligence is considered the natural progression from Artificial General Intelligence (AGI) because it encompasses capabilities beyond human capacities. This includes advanced decision-making, rational reasoning, and even aspects such as forming emotional connections. The distinction between AGI and ASI lies in the marginal difference in their capabilities and the extent to which they surpass human intelligence.
Artificial Neural Network (ANN) is a computational model utilized in machine learning that draws inspiration from the biological structure and functionality of the mammalian brain. This model comprises interconnected units known as artificial neurons, which facilitate the transmission of information. The notable benefit of this model is its ability to progressively “learn” tasks from provided data without requiring specific programming for individual tasks.
Artificial Neurons: An artificial neuron is a digital representation designed to mimic the functioning of a biological neuron found in the human brain. These artificial neurons are commonly utilized as building blocks in artificial neural networks, which aim to replicate human brain functions and activities.
Asimov: Isaac Asimov’s Three Laws are as follows:
(1) A robot may not injure a human being.
(2) A robot must obey orders unless they conflict with law number one.
(3) A robot must protect its own existence, as long as those actions do not conflict with either the first or second law.
Association: A subcategory within unsupervised learning can be illustrated through market basket analysis (MBA). MBA aims to discover relationships and associations between different items selected by a specific shopper and placed in their respective baskets, whether physical or virtual. The outcome of this analysis is useful for cross-marketing products and analyzing customer behaviour. The association represents the broader concept behind MBA. For instance, if a customer has already purchased milk and eggs, there is a high likelihood that they will also buy bread—an example of association.
Augmented Intelligence: Augmented Intelligence refers to the convergence of machine learning and advanced applications, where clinical expertise and medical data come together on a unified platform. The true advantages of Augmented Intelligence are realized when it is integrated into the workflows and systems that healthcare professionals utilize and engage with. In contrast to Artificial Intelligence, which aims to replicate human intelligence, Augmented Intelligence collaborates with and enhances human intelligence.
Autoregressive Model: An autoregressive model is a type of time series model that employs past observations as inputs in a regression equation to forecast the value at the subsequent time step. In the domains of statistics and signal processing, an autoregressive model serves as a representation of a specific category of random processes. It is utilized to describe various time-varying phenomena in fields such as nature, economics, and more.
AI Ops: AI-driven optimization of IT operations entails the identification and detection of anomalies within IT system logs and metrics. It involves the grouping of various events or alerts, diagnosing problems, and resolving issues based on learned actions from past incidents, tickets, and similar sources. Additionally, AI ops focuses on monitoring and enhancing application performance while proactively preventing potential issues or incidents from occurring.
Automatic Speech Recognition (ASR): Speech recognition technology possesses the capability to transform spoken language, represented by an audio signal, into written text, often employed as a command. Cutting-edge software available today exhibits high accuracy in processing diverse dialects and accents. This Automatic Speech Recognition (ASR) technology finds widespread use in user-facing applications like virtual agents, live captioning, and clinical note-taking, where precise speech transcription plays a vital role. In the speech AI domain, developers may employ alternative terms such as ASR, speech-to-text (STT), and voice recognition interchangeably to refer to speech recognition. ASR holds significant importance as a fundamental element of speech AI, which comprises a suite of technologies aimed at facilitating human-computer interaction through voice-based communication.
Automated Machine Learning (AutoML): Automated machine learning (AutoML) refers to the application of machine learning models to real-world problems through the use of automation. It involves automating the selection, composition, and parameterization of machine learning models. By automating the machine learning process, AutoML makes it more accessible and user-friendly, often yielding faster and more accurate outputs compared to manually coded algorithms.
AutoML software platforms play a crucial role in enhancing the user-friendliness of machine learning and providing organizations without dedicated data scientists or machine learning experts with the ability to leverage machine learning capabilities. These platforms can be obtained from third-party vendors, accessed through open-source repositories like GitHub, or developed in-house.
Automation Bias: Automation bias refers to the tendency to excessively rely on automated aids and decision support systems. With the increasing availability of automated decision aids in critical decision-making contexts such as intensive care units and aircraft cockpits, this bias becomes more prevalent. It is a natural inclination for humans to opt for the path of least cognitive effort, leading to a reliance on automation. This concept also aligns with the fundamental principles of AI and automation, which heavily rely on learning from vast datasets. However, this approach assumes that the future will not deviate significantly from the past. It is crucial to consider the potential risks associated with using flawed training data, as this can result in flawed learning outcomes.
B
Back Propagation: Backpropagation, alternatively known as “backward propagation of errors,” is a widely employed technique in the training of deep neural networks to minimize errors. It enables the machine-learning algorithm to make adjustments by examining its previous functionality. The process involves computing the errors between predictions and target values, calculating the gradient of the error function, and subsequently updating the weights. Backpropagation is closely associated with feedforward neural networks, as it facilitates the propagation of error information from the output layer back to the input layer, enabling iterative adjustments for improved accuracy.
Backward Chaining: Backward chaining, known as a goal-driven inference technique, is an inference method that operates by reasoning in reverse from the desired goal to the conditions necessary to achieve that goal. This approach of backward chaining is widely utilized in various domains, such as game theory, automated theorem proving, and artificial intelligence. By working backwards from the desired outcome, backward chaining enables the determination of the conditions or steps needed to reach the goal, allowing for effective problem-solving and decision-making processes.
Baseline: A baseline model refers to a straightforward and easily constructed model that yields reasonable results for a given task without demanding extensive expertise or time investment. These baseline models serve as initial benchmarks and are commonly employed in various scenarios. For instance, linear regression is often utilized for predicting continuous values, logistic regression is applied to classify structured data, pre-trained convolutional neural networks are used for vision-related tasks, and recurrent neural networks and gradient-boosted trees prove beneficial for sequence modeling. Baseline models provide a starting point for comparison and serve as a foundation for further improvements and advancements in modeling.
Batch Size: The batch size is a hyperparameter that determines the number of samples processed before updating the internal model parameters.
Visualize a batch as a for-loop that iterates over one or multiple samples, generating predictions. Once the batch is complete, the predictions are compared to the expected output variables, resulting in an error calculation. Using this error, the update algorithm is employed to enhance the model by adjusting its parameters along the error gradient.
A training dataset can be divided into one or more batches, each comprising a specific number of samples. If the entire training dataset is used to form a single batch, the learning algorithm is known as batch gradient descent. On the other hand, when the batch size is set to one sample, the learning algorithm is referred to as stochastic gradient descent. For batch sizes greater than one sample but smaller than the size of the training dataset, the learning algorithm is called mini-batch gradient descent.
- Batch Gradient Descent. Batch Size = Size of Training Set
- Stochastic Gradient Descent. Batch Size = 1
- Mini-Batch Gradient Descent. 1 < Batch Size < Size of Training Set
In the case of mini-batch gradient descent, popular batch sizes include 32, 64, and 128 samples. You may see these values used in models in the literature and in tutorials.
C
Classification: A process in machine learning where inputs are categorized into two or more classes. For example, an email spam filter classifies incoming emails as “spam” or “not spam” based on their content, sender, and other attributes.
Clustering: A type of unsupervised learning that groups a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. For instance, customer segmentation in marketing can use clustering to group customers based on purchasing behavior and preferences.
Convolutional Neural Network (CNN): A deep learning algorithm that can take in an input image, assign importance (learnable weights and biases) to various aspects or objects in the image, and differentiate one from the other. CNNs are widely used in image and video recognition, recommender systems, and image classification.
Cross-Validation: A technique for evaluating ML models by training several ML models on subsets of the available input data and evaluating them on the complementary subset of the data. For example, in k-fold cross-validation, the original sample is randomly partitioned into k equal-sized subsamples; of the k subsamples, a single subsample is retained as the validation data for testing the model, and the remaining k − 1 subsamples are used as training data.
Chatbots: AI programs designed to simulate a conversation with human users, especially over the Internet. They are used in customer service to handle simple tasks and frequently ask questions efficiently, like answering queries about bank account balances or store hours.
Cognitive Computing: A subset of AI that attempts to mimic human thought processes in a computerized model. It involves self-learning systems that use data mining, pattern recognition, and natural language processing to mimic the way the human brain works.
Collaborative Filtering: A method used by recommendation systems to make automatic predictions (filtering) about the interests of a user by collecting preferences from many users (collaborating). This approach is used by services like Netflix or Spotify to recommend movies or music based on others with similar tastes.
Computer Vision: A field of artificial intelligence that trains computers to interpret and understand the visual world. Using digital images from cameras and videos and deep learning models, machines can accurately identify and classify objects and then react to what they “see.”
Contextual Bandits: A type of problem in reinforcement learning where an agent learns to choose actions (similar to slot machines, or “one-armed bandits”) based on the current state of the environment, with the goal of maximizing some notion of cumulative reward. It’s particularly useful in personalized web content recommendations, where the algorithm must balance the trade-off between exploring new content and exploiting known popular content.
Curriculum Learning: A type of learning where the tasks are presented in a meaningful order that progresses from easier to harder. This technique is inspired by the way humans learn, making the training process for AI more efficient and potentially more effective.
Causality: The relationship between cause and effect. In AI and data science, understanding causality is crucial for making predictions about the effects of potential interventions. For example, a healthcare AI system might analyze patient data to determine which treatment options have caused improvements in similar patients in the past.
Cost Function: In optimization, cost functions or loss functions are used to define and quantify the error of a model. The goal of training an AI model is often to minimize the cost function, which measures the difference between the model’s prediction and the actual data.
D
Data Mining: The process of discovering patterns and knowledge from large amounts of data. The data sources can include databases, data warehouses, the web, and other sources. For instance, businesses use data mining to discover relationships among internal factors like price, product positioning, or staff skills, and external factors like economic indicators, competition, and customer demographics.
Data Preprocessing: Involves cleaning and transforming raw data before processing and analysis. Steps include dealing with missing values, normalizing data, encoding categorical variables, and more to make the data suitable for a machine learning model. An example would be adjusting diverse data formats into a single standard format.
Deep Learning: A subset of machine learning involving neural networks with multiple layers. Deep learning models can learn complex patterns in large amounts of data, which makes them particularly useful for tasks such as image and speech recognition. For example, a deep learning model can be trained to recognize objects in images with high accuracy by processing vast numbers of images through its layers.
Decision Tree: A model used for both classification and regression. It represents decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It’s like a flowchart where each internal node represents a “test” on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label or decision taken after computing all attributes.
Dimensionality Reduction: The process of reducing the number of random variables under consideration by obtaining a set of principal variables. Techniques like Principal Component Analysis (PCA) are used to reduce the dimensions of large data sets, improving the efficiency of data processing for machine learning models.
Discriminative Model: A type of model that attempts to draw boundaries in the data space. For example, logistic regression or a support vector machine (SVM) is a discriminative model because it attempts to differentiate between classes of data.
Distributed AI (DAI): Refers to the distributed systems where multiple AI agents collaborate to solve problems or make decisions. This can include multi-agent systems where agents work together to achieve a common goal, such as in distributed sensing networks or collaborative robotics.
Dropout: A regularization technique for reducing overfitting in neural networks by preventing complex co-adaptations on training data. It works by randomly dropping out (i.e., setting to zero) many output features of the layer during training.
E
Early Stopping: A regularization technique used in machine learning to prevent overfitting when training a model iteratively (like a neural network). Training is halted when the model’s performance on a separate validation dataset starts to degrade.

Edge AI: The deployment and execution of AI algorithms and models directly on edge devices (like smartphones, sensors, robots) rather than relying solely on cloud computing. This enables faster processing, lower latency, and improved privacy.
Embedding: A relatively low-dimensional vector representation of a higher-dimensional object (like words, documents, images, or users). These representations capture semantic relationships and similarities between the objects.
Embodied AI: AI agents that exist in and interact with a physical environment through sensors and actuators (like robots or virtual agents with bodies). Their intelligence is developed through interaction with the real or simulated world.
Encoder: A part of a neural network architecture, often used in tasks like machine translation and image captioning. It processes an input sequence (e.g., text, image) and transforms it into a fixed-length representation (embedding or context vector).
Encoder-Decoder Model: A neural network architecture commonly used for sequence-to-sequence tasks. It consists of an encoder that processes the input sequence and a decoder that generates the output sequence based on the encoder’s representation.
Environment (Reinforcement Learning): The external system or world with which an agent interacts in reinforcement learning. The agent observes the environment’s state and takes actions within it.
Epoch: One complete pass through the entire training dataset during the training of a machine learning model. Multiple epochs are often required for the model to learn effectively.
Evaluation Metric: A quantitative measure used to assess the performance of a machine learning model on a given task (e.g., accuracy, precision, recall, F1-score for classification; Mean Squared Error for regression).
Explainable AI (XAI): A field of AI focused on developing methods and techniques that make the decisions and reasoning of AI systems understandable and transparent to humans. This is crucial for building trust and accountability.
Expert System: An early form of AI that attempts to mimic the decision-making ability of a human expert in a specific domain. It typically relies on a knowledge base of rules and facts.
Exploding Gradient Problem: A challenge encountered during the training of deep neural networks where the gradients (used to update the network’s weights) become excessively large, leading to unstable training and potentially preventing convergence.
Exploration vs. Exploitation (Reinforcement Learning): A fundamental dilemma in reinforcement learning. Exploration involves trying out new actions to discover potentially better rewards, while exploitation involves choosing actions that are known to yield good rewards based on experience.
Extractive Summarization: A text summarization technique that identifies and extracts key phrases and sentences directly from the original text to form a concise summary.












