
In the realm of artificial intelligence and natural language processing, the integration of external knowledge into large language models (LLMs) has become increasingly vital. The paper titled “HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems” by Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen presents a novel approach to this challenge by advocating for the use of HTML as a format for retrieved knowledge in Retrieval-Augmented Generation (RAG) systems.
This article will delve into the main concepts and findings of the paper, providing a comprehensive overview for readers.
Background on RAG Systems
By adding external knowledge gathered from multiple sources, mostly the internet, RAG systems improve LLMs. HTML documents are usually converted to plain text by traditional RAG frameworks before being fed into LLMs. However, important structural and semantic elements included in HTML, such as headings and tables, are sometimes lost during this conversion. According to the authors, keeping this data is crucial for enhancing LLM performance and lowering problems like hallucinations, which occur when models produce inaccurate or illogical results.

The Proposal: HtmlRAG
The approach that the authors suggest, HtmlRAG, uses HTML directly rather than transforming it into plain text. According to their theory, the model’s comprehension and generating capabilities can be greatly improved by adopting HTML since it preserves more semantic and structural information.
Advantages of Using HTML
- Preservation of Information: HTML contains rich structural elements that provide context to the data. For instance, tables and lists in HTML convey relationships and hierarchies that are lost when converted to plain text.
- LLM Compatibility: Many LLMs have been pre-trained on HTML data, giving them an inherent ability to understand this format without requiring extensive fine-tuning.
- Longer Context Handling: With advancements in LLM architectures allowing for longer input sequences, utilizing HTML becomes feasible despite its typically larger size compared to plain text.
Challenges with HTML Utilization:
While the advantages are clear, using HTML also presents challenges:
- Excessive Input Length: Real-world HTML documents can be lengthy, containing unnecessary tokens such as CSS styles and JavaScript code that do not contribute to the semantic meaning.
- Noise Management: The presence of irrelevant content can degrade the quality of outputs generated by LLMs.
Proposed Solutions:
To address these challenges, the authors introduce several strategies:
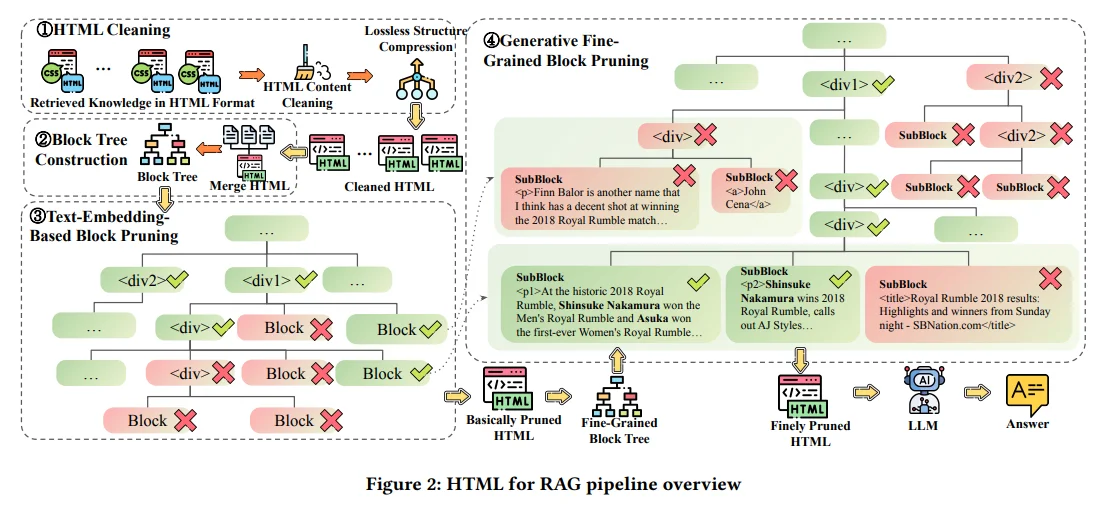
1. HTML Cleaning: This module aims to remove non-essential elements from HTML documents while preserving the core content. By cleaning up the document structure, they significantly reduce its size to about 6% of its original length while maintaining relevant information.
2. Two-Step Pruning Method: The pruning process is designed to further refine the cleaned HTML:
- Building a Block Tree: The authors convert the DOM (Document Object Model) tree of an HTML document into a block tree structure, merging nodes into hierarchical blocks for efficiency.
- Relevance-Based Pruning: Using embedding models, they assess the relevance of each block to the user’s query. Blocks with lower relevance scores are pruned away.
- Generative Fine-Grained Block Pruning: This step involves a generative model that evaluates finer-grained blocks based on their semantic relevance, allowing for more precise pruning.

Experimental Validation:
The authors conducted experiments across six question-answering datasets to validate their approach. The results demonstrated that using HTML as a knowledge format outperformed traditional plain text methods in terms of effectiveness and efficiency.

End Note:
The work described in “HtmlRAG” represents a major breakthrough in the integration of external knowledge into RAG systems. By recommending HTML over plain text, the authors draw attention to a technique that improves LLM performance while simultaneously protecting important data. More advanced applications in AI-driven knowledge generation and retrieval may be made possible by this strategy.
In conclusion, HtmlRAG highlights the significance of preserving structural integrity in data formats utilized by LLMs and offers a viable avenue for further study and advancement in retrieval-augmented systems.













