Discover the revolutionary VideoPoet, a large language model (LLM) redefining the landscape of video generation. Tackling the challenge of coherent large motions, VideoPoet stands out by seamlessly integrating multiple video generation tasks within a single model, setting it apart from diffusion-based counterparts.
Google's VideoPoet: A Groundbreaking Multimodal AI Tool for Next-Gen Video Generation
The realm of video generation models has captivated audiences with breathtaking quality, yet a bottleneck persists in producing coherent large motions without noticeable artifacts. Enter VideoPoet, an innovative Large Language Model (LLM) designed to explore the vast potential of language models in video generation.
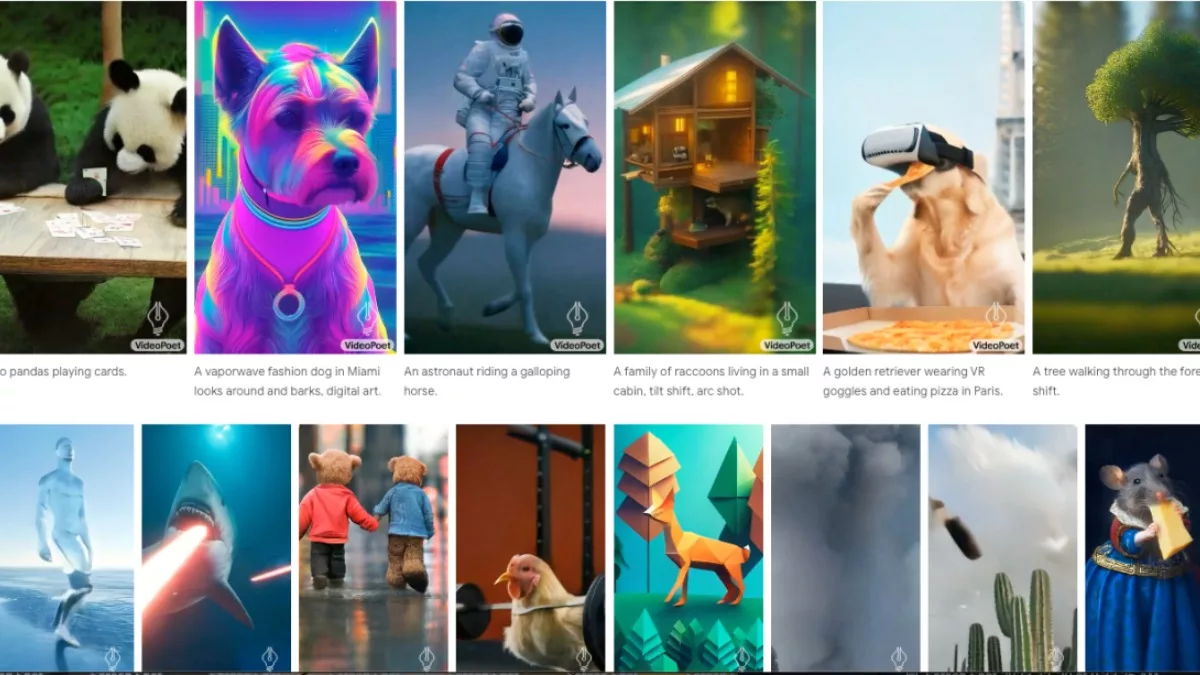
VideoPoet excels in diverse video generation tasks like text-to-video, image-to-video, video stylization, inpainting, outpainting, and even video-to-audio. Unlike leading diffusion-based models, VideoPoet’s strength lies in its unified approach, consolidating various capabilities within a single LLM rather than relying on separately trained components.
The training process involves an autoregressive language model trained across video, image, audio, and text modalities using multiple tokenizers, such as MAGVIT V2 for video and image and SoundStream for audio. The resulting model can generate variable-length video outputs with diverse motions and styles, depending on the input text content.
Must Read: Google’s Gemini AI Fake Video: The Deceptive Demo Video and Trust Deficit
VideoPoet’s text-to-video outputs vary in length, applying diverse motions and styles based on the input text. Responsible practices are ensured by referencing public domain artworks and styles, such as Van Gogh’s “Starry Night,” for inspiration. The model extends its prowess to video stylization, predicting optical flow and depth information guided by additional input text, and even audio generation from video.
Also Read: Google Integrates YouTube to Bard: Check Here how it works and help users
In default portrait orientation, VideoPoet tailors its output for short-form content. A captivating movie, featuring short clips generated by VideoPoet, showcases its capabilities. A traveling raccoon short story was crafted to demonstrate the model’s versatility, generating video clips for each prompt.
Must Read: Google Gemini vs OpenAI ChatGPT 4: Who is the Winner in Text, Audio, and Video Capabilities?
VideoPoet’s ability to extend videos by predicting subsequent seconds and interactive editing of existing clips further exemplifies its capabilities. Object motion can be altered, allowing for nuanced actions, and image-to-video control enables content editing based on text prompts.
Accurate camera motion control is achieved by appending desired camera motions to text prompts. Evaluation results underscore VideoPoet’s superiority in text-to-video generation, with users consistently preferring its output for interesting motion over competing models.
VideoPoet demonstrates the significant potential of LLMs in video generation, offering a glimpse into a future where “any-to-any” generation, from text-to-audio to video captioning, becomes seamlessly achievable. The model’s comprehensive capabilities open avenues for exciting developments, promising a new era in video content creation.
Must Read: Beginning of Google’s Gemini Era: 10 amazing things Gemini can do
This post was last modified on December 21, 2023 10:06 am
Pick your task, get the best AI model for it — images, video, slides, research,…
Learn what Agentic AI is, how it works, and how it differs from Generative AI.…
Discover the 13 best free online vocal remover AI tools for 2026, designed to isolate…
Explore the top 13 yield farming platforms for 2026, featuring secure, trusted, and high-APY crypto…
Explore the best AI learning platforms for 2026, including Coursera, edX, Udacity, and more. Learn…
Explore the 13 best Polygon wallets in 2026, comparing security, DeFi access, hardware and mobile…