Integrating external knowledge into large language models (LLMs) is essential in AI. The paper "HtmlRAG" introduces a novel method, advocating HTML over plain text for enhanced knowledge retrieval in Retrieval-Augmented Generation (RAG) systems, improving model accuracy and structure.
HtmlRAG: HTML is Better Than Plain Text
In the realm of artificial intelligence and natural language processing, the integration of external knowledge into large language models (LLMs) has become increasingly vital. The paper titled “HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems” by Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen presents a novel approach to this challenge by advocating for the use of HTML as a format for retrieved knowledge in Retrieval-Augmented Generation (RAG) systems.
This article will delve into the main concepts and findings of the paper, providing a comprehensive overview for readers.
By adding external knowledge gathered from multiple sources, mostly the internet, RAG systems improve LLMs. HTML documents are usually converted to plain text by traditional RAG frameworks before being fed into LLMs. However, important structural and semantic elements included in HTML, such as headings and tables, are sometimes lost during this conversion. According to the authors, keeping this data is crucial for enhancing LLM performance and lowering problems like hallucinations, which occur when models produce inaccurate or illogical results.
The approach that the authors suggest, HtmlRAG, uses HTML directly rather than transforming it into plain text. According to their theory, the model’s comprehension and generating capabilities can be greatly improved by adopting HTML since it preserves more semantic and structural information.
While the advantages are clear, using HTML also presents challenges:
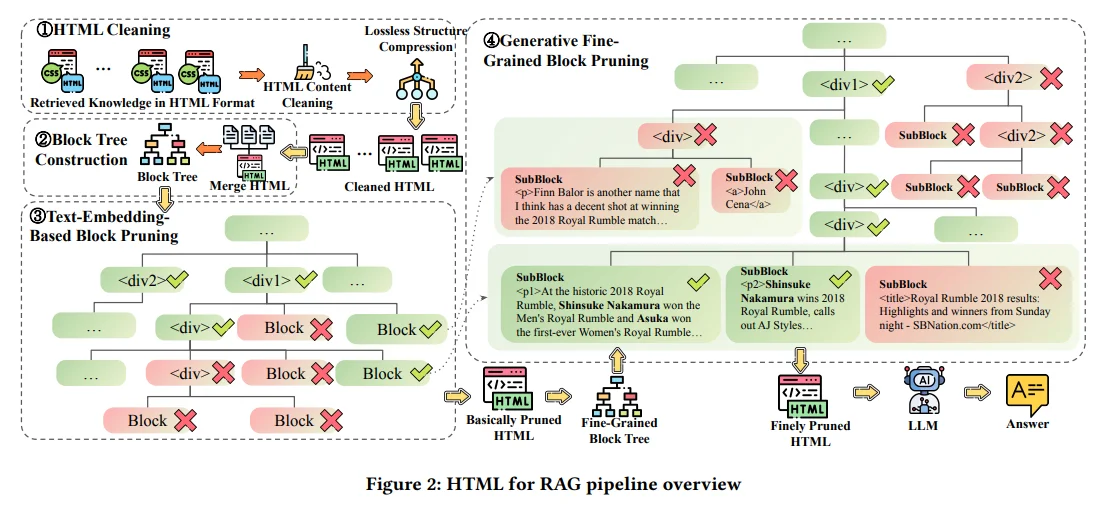
To address these challenges, the authors introduce several strategies:
1. HTML Cleaning: This module aims to remove non-essential elements from HTML documents while preserving the core content. By cleaning up the document structure, they significantly reduce its size to about 6% of its original length while maintaining relevant information.
2. Two-Step Pruning Method: The pruning process is designed to further refine the cleaned HTML:
The authors conducted experiments across six question-answering datasets to validate their approach. The results demonstrated that using HTML as a knowledge format outperformed traditional plain text methods in terms of effectiveness and efficiency.
The work described in “HtmlRAG” represents a major breakthrough in the integration of external knowledge into RAG systems. By recommending HTML over plain text, the authors draw attention to a technique that improves LLM performance while simultaneously protecting important data. More advanced applications in AI-driven knowledge generation and retrieval may be made possible by this strategy.
In conclusion, HtmlRAG highlights the significance of preserving structural integrity in data formats utilized by LLMs and offers a viable avenue for further study and advancement in retrieval-augmented systems.
This post was last modified on November 6, 2024 6:40 am
Pick your task, get the best AI model for it — images, video, slides, research,…
Learn what Agentic AI is, how it works, and how it differs from Generative AI.…
Discover the 13 best free online vocal remover AI tools for 2026, designed to isolate…
Explore the top 13 yield farming platforms for 2026, featuring secure, trusted, and high-APY crypto…
Explore the best AI learning platforms for 2026, including Coursera, edX, Udacity, and more. Learn…
Explore the 13 best Polygon wallets in 2026, comparing security, DeFi access, hardware and mobile…
